3️⃣PEFT: Fine-tuning with QLoRA
Fine-tune Quantization 종류
Fine-tuning Quantization Model
양자화에서 정확도가 그대로 재현
특정 사용 사례 및 애플리케이션에 맞게 모델의 Fine-tuning 동시에 가능
QAT: Fine-tune with Quantization Aware Training
정량화된 버전이 최적의 성능을 발휘할 수 있도록 모델을 미세 조정 합니다.
Post Training Quantization(PTQ) 기법과는 호환되지 않습니다.
Linear Quantization(선형 양자화) 방법은 PTQ의 예입니다.
PEFT(Parameters efficient fine-tuning)
전체 미세 조정과 동일한 성능을 유지하면서 모델의 학습 가능한 매개변수 수를 대폭 줄일 수 있습니다.
대표적으로 PEFT +QLoRA 활용: https://pytorch.org/blog/finetune-llms/
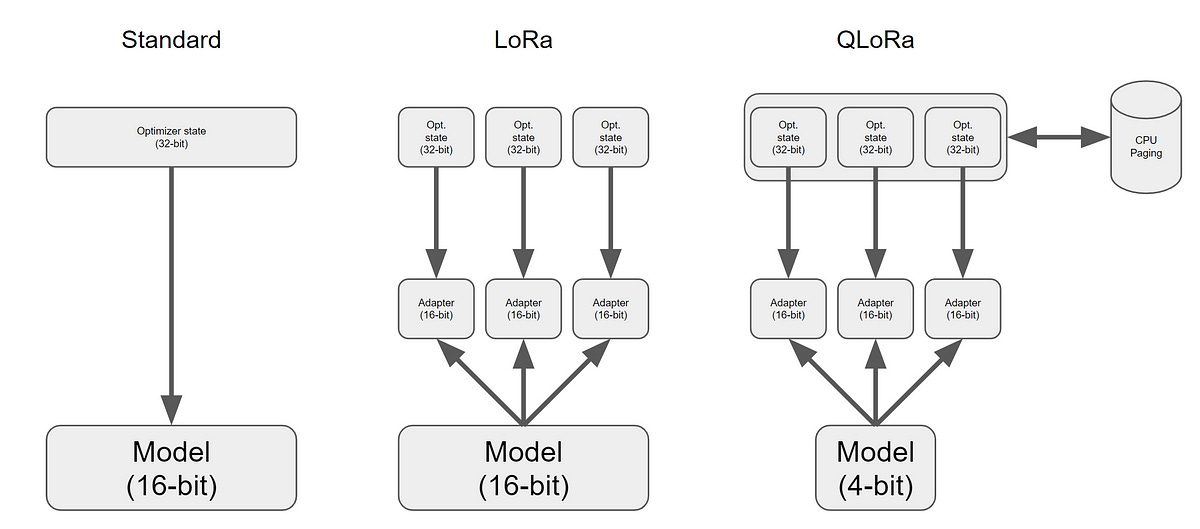
QLoRA
QLoRA (Quantized Low-Rank Adaptation)은 BERT와 같은 대규모 사전 훈련된 언어 모델을 Adaper에서 Parameter Efficient Finetuning (PEFT) 접근 방식의 확장입니다.
Pre-trained 모델을 고정한 상태에서 새로운 작업별 레이어를 추가하는 대신 기존 상위 레이어를 적응시킵니다. 이러한 레이어는 가중치 행렬을 양자화(Quantized)하고 Low-Rank 근사치로 분해함으로써 더 효율적으로 만들어집니다.
QLoRA 접근 방식에서는 원래 모델의 가중치가 4 bit presicion 으로 양자화됩니다. 새로 추가된 Low-rank Adapter (LoRA) 가중치는 양자화되지 않으며 더 높은 정밀도로 유지되며 훈련 과정에서 세세하게 조정됩니다. 이 전략을 통해 세세한 조정 중에도 대규모 언어 모델의 성능을 유지하면서 효율적으로 메모리를 사용할 수 있습니다.
QLoRA는 사전 학습 된 기본 가중치(그림의 blue 컬러)를 4비트 정밀도로 정량화합니다.
Low Rank Adaptor(LoRA) 가중치의 정밀도(그림의 orang 컬러)와 일치합니다.
모델은 사전 학습된 가중치(blue)와 어댑터 가중치(orange)의 활성화를 추가할 수 있습니다.
이 두 활성화의 합은 네트워크의 다음 계층에 입력으로 제공될 수 있습니다.
PEFT Fine-tune with QLoRA
Transformer: 가장 먼저 설치해야 할 것은 바로 이 라이브러리입니다. 사전 학습된 모델을 다운로드, 학습 및 미세 조정할 수 있는 라이브러리입니다.
Datasets: 라이브러리를 통해 JSON, CSV, Parquet, 텍스트 및 기타 형식의 데이터 세트를 로드할 수 있습니다.
TRL - 라이브러리에서는 모델의 지도 학습을 허용합니다. 구조화된 데이터 세트가 있는 경우 이러한 유형의 훈련을 구현해야 합니다.
PEFT - 파라미터 효율적 미세 조정 기술은 사전 학습된 LLM의 대부분의 파라미터를 동결하면서 소수의 (추가) 모델 파라미터 또는 가중치를 미세 조정합니다. 전체 LLM을 미세 조정하려면 엄청난 하드웨어가 필요하고 에너지 소모가 크지만 PEFT를 사용하면 일반 소비자용 GPU에서 거대한 LLM을 미세 조정할 수 있기 때문에 이는 매우 중요합니다. 로라 또는 대규모 언어 모델의 로우랭크 적응은 광범위한 PEFT 기술 범주에 속하는 특정 방법입니다. 이 방법은 사전 학습된 모델 가중치를 동결하고
bitsandbytes
acecelerate: 라이브러리를 사용하여 모델을 정량화하는 데 사용됩니다.
Setup Environments
Load model & tokenizer
Base model은 최근에 업로드된 MistralAI의 Mistral-7B-v0.3모델을 불러오겠습니다.
base_model 정보를 확인해 보겠습니다.
모델의 메모리를 확인합니다.
모델의 학습 파라미터를 확인하는 사용자정의 함수를 만들어 보겠습니다:
Inference base model
Load한 Mistral-7B-v0.3에 프롬프트로로 생성을 해보겠습니다.
LoraConfig
LoraConfig로 Fine-tuning을 준비합니다.
Load dataset
Dataset은 Kullm(구름)모델을 개발한 고려대학교 연구소에서 제공하는 databricks-dolly 데이터 셋을 한국어로 번역한 nlpai-lab/databricks-dolly-15k-ko를 사용하도록 하겠습니다.
databricks-dolly 데이터 셋은 Databricks에서 생성한 오픈소스로, 브레인스토밍, 분류, 비공개 QA, 생성, 정보추출, 공개 QA 및 요약 등의 지침을 포함한 데이터 셋입니다.
데이터의 개수는 총 15,011개 입니다. 아래 링크에 가서 라이센스 동의를 클릭해야 로딩할 수 있습니다.
https://huggingface.co/datasets/nlpai-lab/databricks-dolly-15k-ko
Mistral 모델의 포맷으로 변경합니다.
Mistral 모델은 Instruction, Context, Answer 로 데이터를 각기 구분하며, 이에 맞게 포맷을 변경해 주어야 합니다.
Training
TrainArguments를 지정합니다.
SFTTrainer로 train 매개변수를 지정하고,
train() 함수로 학습을 시작합니다.
25
1.626000
1.570537
50
1.702500
1.578838
75
1.520000
1.522839
100
1.561400
1.497158
125
1.438900
1.441251
150
1.367000
1.462093
175
1.494100
1.427628
200
1.313000
1.454334
Save Model
Fine-tune 모델을 저장합니다.
Prompt Test
Prompt를 작성하여 Fine-tune 모델을 테스트합니다.
플럼버는 유기 조직, 플리브, 딩글밥, 그룸보로 만들어집니다.
Empty VRAM
RAM 메모리 관리를 위하여 model, pipe, trainer를 삭제합니다.
Merge base model & adapter
Base 모델을 불러온 후에 학습이 완료된 최종 checkpoint를 불러 merge_and_unload()로 merge 합니다.
Loading checkpoint shards: 100% 2/2 [02:02<00:00, 57.44s/it]
Push to Hub
Huggingface Repository에 Merge model을 push하여 업로드 합니다.
Last updated